

前言
这几年网上已经有非常的多文章在探讨 React 这次的大手笔, 正好借在 Bench 这段时间里能通过 React18 的源码看看到底做了哪些改变, 主要是对时间切片和调度方面比较感兴趣
接着就git clone -> setup 源码 -> 添加beakPoint 一顿操作猛如虎, 然后发现 emmm… 根本无从下手…
React 的代码量既多, 跳转逻辑又很复杂. 所以果断换思路从设计思想出发, 再到实现. 起码你先知道 React_ _想做什么, 在看咋实现的不容易多了吗(是吗?😒)
于是打开浏览器 Google: React 的设计思想, 第一个蹦出来的就是今天的主角: 代数效应
听上去是个很可怕的名字…
引用一位 React 的核心开发者 Sebastian Markbåge 的话
React 所做的事就是在践行代数效应
为了更好得理解代数效应, 我们先来看看与之相关的一个东西: CPS
Continuation Passing Style (CPS)
1 | const add = (x, y) => { |
1 | const add = (x, y, next) => { |
对比之下, 我们可以发现: 好家伙! CPS 不就是我们嗤之以鼻的回调地狱吗! 而且可读性奇差
既然这样那我们为什么还要写 CPS 呢? 答案是: 不用写, 但是并不代表 CPS 就是一无是处的.
抛弃刚刚对 CPS 的有色眼镜, 重新观察分析一下 CPS 到底有什么优势
1. Continuation
在上面的例子中, 每个函数都接收一个next回调函数, 而且每个函数的计算结果都是通过next延续(细品延续这个词)给下一个函数.
顺着这个思路再来看与 CPS 对比的 Direct Style, 它对流程的控制完全取决于我们调用啥. 所以它对延续性(continuation)的控制是隐式的, 不像 CPS 我们一看到next就知道这是要控制流程继续往下延续了.
换句话说 CPS 能控制程序后续的流程
2. 同时兼容同步和异步处理
还是利用上面的例子, 假如现在新增一个需求 add 后需要等待 2 秒再执行, 对于 Direct Style 我们必须对 add 后续的整个流程进行调整1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19const add = (x, y) => {
return x + y
}
const subtract = (x, y) => {
return y - x
}
const multiply = (a, b) => {
return a * b
}
const result1 = add(1, 2)
setTimeout(() => {
const result2 = subtract(result1, 1)
const result3 = multiply(result2, 3)
console.log(result3) // 6
}, 2000)
对于 CPS 则只需要改变next的调用时机即可1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17const add = (x, y, next) => {
next(x + y)
}
const subtract = (x, y, next) => {
setTimeout(next, 2000, y - x)
}
const multiply = (a, b, next) => {
next(a * b)
}
add(1, 2, (result1) => {
subtract(result1, 1, (result2) => {
multiply(result2, 3, console.log) // 6
})
})
可以看出这样的改动对于 CPS 来说, 并不需要改动到主流程.
3. Tail Call
CPS 同时也是尾调用, 只不过 JS 引擎并不支持这种优化, 在此也不展开了
那么 CPS 对于流程控制有这么强大的力量, 但是又碍于它反人类的书写方式不能使用. 那在 JS 中有没有什么办法能解决这个书写的问题呢?
Promise1
2
3
4
5
6
7
8
9
10
11const add = (x, y) => Promise.resolve(x + y)
const subtract = (x, y) => delay(2000).then(() => y - x)
const multiply = (a, b) => Promise.resolve(a * b)
const delay = (milli) => new Promise(resolve => setTimeout(resolve, milli))
add(1, 2)
.then(res => subtract(res, 1))
.then(console.log)
也许你还想到了 Generator, 没错 Generator / Promise / async/await 都是 CPS 的变形. 如果你再留心一点就会发现 Promise.resolve / Generator.next 其实都是 CPS 中的 next
总结
一句话 CPS 对流程控制非常牛逼, 不论是同步任务还是异步任务都拿捏的死死的
Algebraic Effect
前面我们介绍了在 JS 中应用 CPS 的姿势, 但即使这样, 我们在 JS 中使用 CPS 依然很繁琐.
如果你用了 Promise 那么你的控制流都得是 Promise; 如果用Generator 都要包裹在 Generator 中; async/await 也是一样. 就像很多文章中提到的一样, 这些方式都具有”传染性”, 它们会由内到外的层层污染, 那么必然就会给开发者带来大量的心智负担
那有没有更便捷的方式来实现呢, 想想在JS 环境下有哪些能够控制流程的方式呢?if/else/ break/throw/switch… 嗯? throw🤔 好像跟其他控制有些不一样, 它可以跳过后续流程(穿透调用栈)! 这似乎有点加强 CPS 那味儿了
回忆一下: 使用 throw时会在调用处中断, 将 throw后面的语句穿透到最近的 try/catch中从而被捕获.
PS: 虽然规范告诉我们
throw出来的必须是个Error对象, 但实际throw可以抛出任意数据类型
1 | function taskA () { |
换句话说, 通过throw将执行流程转移至catch代码块, 这就是所谓的 Control Transfer 控制转移
如果我们把两者结合一下, 试想将 CPS 的next通过throw操作符将控制流转移至 catch中. 这样既解决了 CPS 可读性的问题, 同时也可以避免 “传染”; 除此之外, 还隔离了函数中的副作用. 实际上这”基本上”就是代数效应所蕴含的思想了
为什么要说是”基本上呢”? 因为这里还有个问题, 那就是在 JS 中throw后就中断了, 不能延续(或者恢复)当前控制流(也就是 CPS 中的 Continuation). 所以很多其他文章中都天马行空地造了一些特殊的关键字来尝试解释代数效应, 这里我也使用 Dan Abramov 在文章的示例稍作修改来完整的展示一下理想中的代数效应
1 | function Component() { |
- 伪造
perform关键字替代throw, 相当于 CPS 中 next 变形(类似于 await), 而 perform 后的语句可以像throw一样被抛出 handle替代catch, 形参effect接收perform关键字传递的实参- 伪造的
resume`with`关键字用于恢复当前控制流(getName 中第 4 行), 并回传 ‘Arya Stark’ - 恢复后控制流中 name 的值就变成了 ‘Arya Stark’
所以这段虚构的代码要表达的就是: 对 makeFriends产生的 Effect, 通过 perform由handler处理, 再用resume将结果恢复到函数执行中, 得到新的结果.
之所以要把 CPS 的 next 称作 Continuation, 是希望通过 throw 可以穿透调用栈的特点来获取当前控制流, 所以穿透调用栈(或者说跨调用栈)并不是目的. 而要在 JS 中真正实现获取当前 Continuation 也就是所谓的 callcc 也是可以的, 大致是用 CPS + Generator 实现的, 那么就不得不把所有东西都变成 generator 了,在这儿就不展开了有兴趣可以看看这篇文章capturing-continuations-with-generators.
总结
代数效应就是: 利用 CPS 的流程控制能力实现对后续流程的控制(perform + resume)结合控制转移能力实现跨调用栈捕获当前控制流(try/handle), 改变当前控制流中的 Effect
在提炼一下代数效应的关键点:
- Effect: 代数所产生的的效应
- Handler: 处理效应的逻辑
- Continuation: 延续流程的控制
- Resume: 恢复 + 与之对应的暂停
React & Algebraic Effect
前面铺垫了那么多代数效应的知识, 现在我们就试着看看代数效应在 React 中是如何应用的
Hooks
1 | function Component() { |
可以看到我们只是以 React 的方式改写了上面的示例, 接着再看看改写后是否还满足代数效应的四要素.
- 首先
friendship的初始值被useState定义, 然后根据getName的返回而被makeFriends修改, 那么我们就可以认为makeFriends是friendship产生 Effect 的一个因素 - 而我们选择
useEffect对产生的效应进行处理, 并将friendship作为该 hook 的依赖, 因此可以认为useEffect就是friendship的处理器了
接着我们还可以进一步的封装1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35function useFriends(defaultValue) {
const [friendship, makeFriends] = useState(defaultValue)
useEffect(() => {
Object.keys()
.forEach((key, index, array) => {
if (!friendship[key].friendNames) {
const name = getName(friendship[key])
const userKey = index % 2 === 0 ? array[index + 1] : array[index - 1]
makeFriends((preUsers) => ({
...preUsers,
[userKey]: {...preUsers[name], friendNames: name}
}))
}
})
}, [friendship])
return [friendship]
}
function Component() {
const [friendship, makeFriends] = useFriends({
arya: { name: null },
gendry: { name: 'Gendry' }
})
return (
<div>
friendship:
user1: {friendship.arya.friendNames}
user2: {friendship.gendry.friendNames}
</div>
)
}
这样一来我们的useFriends作为一个具有 Effect 以及处理器的代数, 就可以为任何组件服务了. 不过大家可能注意到了代数效应最酷的resume特性我们并没有看到, 这要如何使用呢?
Fiber
这就得从 Fiber 说起了, 我们都知道React 从 v16 开始就是 Fiber 架构了. 而 Fiber 架构的本质就是利用浏览器空闲时间, 根据任务的优先级分片执行, 更新过程中可以随时暂停和恢复任务.
用下图来概括了React 中的调度流程(整个流程都以开启 Concurrent 模式为例)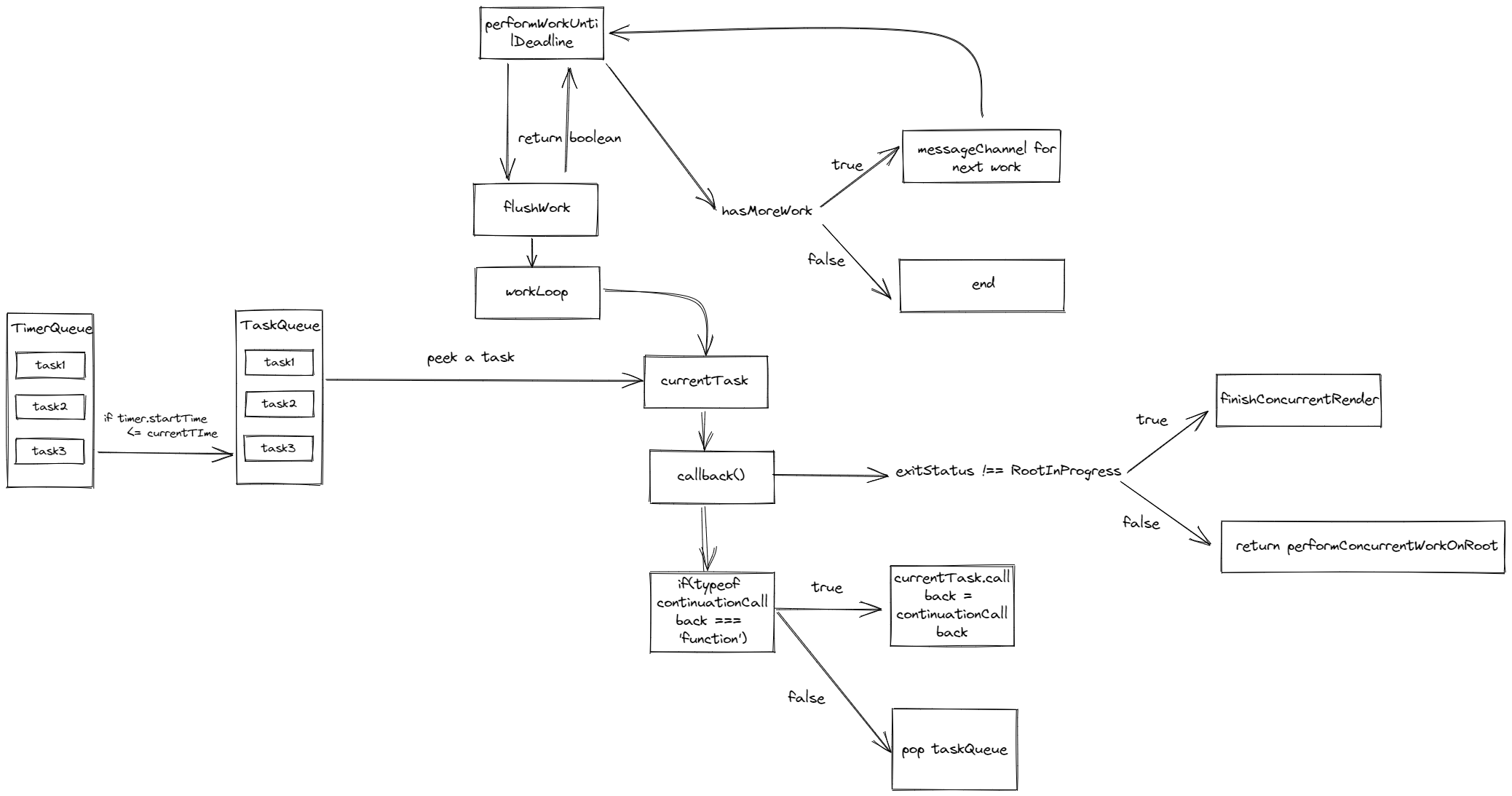
- 更新任务会按照过期时间排序注册在
taskQueue队列中(PS:timerQueue保存延时任务, 等时间到了会放入taskQueue) - 然后通过
performWorkUntilDeadline调用flushWork执行workLoop来执行队列中的任务- 执行
currentTask.callback(也就是performConcurrentWorkOnRoot), 如果更新过程中**shouldYield**为 true 暂停更新 - 那么返回的
exitState === RootInProgress为true, 导致currentTask.callback返回**performConcurrentWorkOnRoot**自身 - 再回到
workLoop拿到currentTask.callback的执行结果continuationCallback也就是performConcurrentWorkOnRoot, 所以if (typeof continuationCallback === 'function')成立. 即保存continuationCallback到currentTask.callback, 不从**taskQueue**移除当前任务, 下个时间切片重新执行
- 执行
- 重复这个过程, 直到队列中的任务执行完毕
大家可能会说, 内部的调度好像也只看到了暂停, 没有恢复啊. 实际上 JS 有个🔨的resume, 所以 React 直接重新执行一遍函数也就是上面的performConcurrentWorkOnRoot, 虽然不是真正意义上的resume但从效果上来说也达到了恢复的目的, 实现类代数效应.
重新执行 performConcurrentWorkOnRoot 函数 React 同时也做了一些优化, 如果你看过 Fiber 节点中的结构, 会发现内部有一个 memorizedProps(更新结束或暂定时定义) 和 pendingProps(更新开始时定义) 属性. 在函数执行过程中会对比这两个属性, 如果两个属性相等就复用上一次的更新结果, 这就是 React 所说的复用已完成的任务结果.
总结
其实从使用 React hooks 来说, 我们不用关心如何使用代数效应. React 内部已经帮我们处理了 continuation和 resume甚至effect, 而我们只需要专注于handle业务逻辑
以 useState 为例:const [count, setCount] = useState()
- 就可以看做
perform state()请求 count 的effect - 由 React 中
shouldYield暂停 Fiber 更新, 等价于暂停当前函数 - 重新执行
continuationCallback等价于resume恢复执行 - 我们需要的业务逻辑
handleeffect
Suspense
React 中的 Suspense 是个更典型的例子, 我们先用官方的例子看看 Suspense 是如何使用的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 这里内部 throw 了一个 Promise
const resource = fetchProfileData();
function ProfilePage() {
return (
<Suspense fallback={<h1>Loading profile...</h1>}>
<ProfileDetails />
<Suspense fallback={<h1>Loading posts...</h1>}>
<ProfileTimeline />
</Suspense>
</Suspense>
);
}
function ProfileDetails() {
// Try to read user info, although it might not have loaded yet
const user = resource.user.read();
return <h1>{user.name}</h1>;
}
function ProfileTimeline() {
// Try to read posts, although they might not have loaded yet
const posts = resource.posts.read();
return (
<ul>
{posts.map(post => (
<li key={post.id}>{post.text}</li>
))}
</ul>
);
}
- 子组件异步读取数据, 将数据渲染在组件中
- 如果数据未加载完毕, React 会暂停渲染该组件, 转而渲染
fallback组件 - 等到数据就绪, 从暂停位置继续渲染子组件
以代数效应来解读
resource.user.read()内部throw promise等价于perform resource.user.read()- react 内部
catch到thenable的函数放进updateQueue更新队列中, 对应组件会被标记为mode: 'hidden'. 相当于暂停了当前函数的执行(PS: 其实这个时候子组件的对应 Fiber 和对应关系已经创建好, 只是放在缓存池了) - 在
promise完成后, React 会在 commit 阶段重新调度渲染子组件, 其实就是恢复执行了.
虽然本质上也不是恢复了函数, 不过在 React 看来这里重新渲染组件和恢复执行没什么区别. 因为在 Suspense 内部不管是 fallback 还是子组件都只会创建一次同时会建立好节点之间的对应关系, 后续 rerender 的时候只是改变了 child 的指针罢了
总结
代数效应本质上就是把”做什么”和”如何做”这两件事儿分离了, 同时提供了对流程控制的能力. React 也是结合了这些特征, 从原来依赖 JS 原生调用栈同步更新方式重构为了现在 Fiber Reconciler 自己模拟了一套组件调用栈/Hooks/Suspense 一系列的新特性. 也印证了 React Hooks 作者的那一句话我们在 React 中所做的事就是在践行代数效应
其实出了 React 以外还有其他库也使用了代数效应作为心智模型, 可以思考看看… 或许…也可以自己造个轮子?