

HTTP 发展至今已经发生了太多的变化, 平常工作中其实并不会注意这些变化, 甚至说根本不关心… 但在前端的工作中却与它密切相关,从通信到性能优化等等. 下面就来聊聊 HTTP
HTTP
主角 HTTP(超文本传输协议), 它的作用就是利用网络将服务端的超文本信息传输给客户端的一种协议. 建立在 TCP 之上, 所以 HTTP 的优化及瓶颈都是基于 TCP 的特性
主要的特点:
- 简单快速: 客户端想服务器请求时, 只需要发送请求方法和路径即可
- 灵活: 支持多种传输格式, 由 Content-Type 控制
- 无连接: 每次连接只处理一个请求-响应, 然后断开连接
- 无状态: 每个 HTTP 之间都是独立/无关的, 不需要保留状态信息
HTTP1.x
HTTP1.x 主要经历两个版本分别是 HTTP1.0 和 HTTP1.1, 而 HTTP1.1 的出现弥补多了很多 1.0 时期的问题.
多个 TCP 连接
1.0 时期每发送一个请求-响应, 都需要重新建立 TCP 连接, 响应完再关闭, 下个请求又要建立再关闭, 所以这是一个非常消耗性能的过程. 这就会带来两个问题:
- 每个请求都需要重新建立 TCP 连接
- 必须等待前一个请求响应了, 后一个请求才能发送, 也就是熟称的
队头阻塞
于是在 1.1 中通过 keep-alive 来避免建立多次 TCP 连接的问题, 在一定时间内复用已经建立的 TCP 连接, 这样在 TCP 连接中可以发送多次请求-响应.
keep-alive 存在的问题:
- 每条 TCP 连接中的请求还是阻塞的(依然是串行文件传输)
- 虽然复用了 TCP 连接, 但浏览器对请求的并发数有 6 ~ 8 条的限制
为了解决串行文件传输的问题, 于是又有了管线化(pipeline).
管线化是基于 keep-alive 通过一个连接把所有请求打包一次性发给服务端, 但响应时还是需要按请求顺序返回. 也就是说如果客户端发送了请求 123, 服务端处理时请求 23 先处理完了, 也必须等到请求 1 处理完才能按顺序应答响应 123, 所以其实也没完全解决问题.
管线化使用队列的方式实现的对性能消耗很大, 因此也是管线化没有被广泛使用的原因
小结: HTTP1.x 搞了这么多还是没解决的队头阻塞的问题, 除了队头阻塞之外, 其实还有明文传输带来的安全问题/ 建立 TCP 带来的连接延时 / 标识链接的五元组在网络切换时带来的链接迁移问题
HTTP2.0
HTTP2.0 在 1.x 的基础上又做了诸多优化, 特别在针对 队头阻塞 的问题上. 下面就分别说说 HTTP2.0 做了些什么
多路复用
主要就是解决 队头阻塞 的问题, 在 2.0 中引进了帧(frame) 和 流(stream) 两个重要的概念.
- 帧(frame): 代表了最小数据的单位, 大体分为: header frame(头部帧) 和 data frame(数据帧)
- 流(stream): 是连接中的虚拟通道, 可以承载双向数据流, 也就是说同一个流中可以同时接收和发送数据, 每个流会有一个唯一的 ID. 同时流中的二进制帧都是并行传输, 无需按顺序等待
多路复用让所有请求都在一个 TCP 中并发完成, TCP 中可以承载不限数量的流, 请求又是基于流的, 流中的消息又由二进制帧组成, 帧会标识属于哪个流, 因此可以做到乱序传输
头部压缩
之前提到 1.x 在传输过程中是通过文本传输的, 在每次传输过程中的很多头部信息都是一样的, 如果再加上一些 cookie 等保存状态的信息, 就会导致头部信息的体积较大, 带来性能上的浪费.
在 2.x 中会用两种方案来解决:
- 用一个叫
HPACK的算法来压缩头部字段的体积 - 发送方和接收方会共同维护一个
头部表, 来防止每次传输相同头部字段. 对重复的头部字段不再每次发送, 当修改或者新增字段再更新这个头部表
服务端推送
1.x 中一个请求只能对应一个响应, 在 2.x 中可以对一个请求响应多个结果. 比如: 请求 HTML 文件时, 服务端可以将 HTML 中用到的资源一并发送回来
当然 HTTP2.x 也不是没有缺点:
- 基于 TCP 的 HTTP 在建立连接依然耗时, 至少都要经历三次握手, 如果有 TLS 时间更长
- 多路复用只解决了 HTTP 层面上的队头阻塞, 而在 TCP 层面上的队头阻塞依然没有解决. 是因为 TCP 为了保证数据的有序性, 要等待所有数据到达后排序整合, 所以一旦发生丢包就必须等待重传, 从而阻塞 TCP 上的所有请求
- 由于多路复用不限制流数量, 导致服务器压力可能会突然暴增, 同时超时的几率也更大
- 网络切换时也无法保持连接
HTTP3.0
基于 HTTP2.x 缺点大多都是 TCP 层面上的特性, 但是如果要改造 TCP 成本和难度都会非常高, 目前已经有非常多的应用是基于 TCP 的, 兼容也是一个比较大的问题. 所以在 HTTP3.0 中就干脆抛弃了 TCP 改用 UDP.
那我们复习一下 UDP 的特性:
- 面向无连接, 没有建立连接的过程
- 面向报文
- 不会保证包顺序或包是否丢失
- 可一对多/多对多等交互通信
可以看到对 TCP 耗时的建连和队头阻塞 UDP 天然就能解决, 改造的负担相对也较小, 那么谷歌就在 UDP 的基础上改造出了一个具备 TCP 有点的 QUIC 协议. QUIC 协议是怎么做到让 UDP “可靠”的呢
低延迟等待
是为了解决 TCP 建立连接至少要 1RTT (三次握手: 一来一回, 再一应答), 如果是 HTTPS 的话那就是 3RTT, 如下图所示:
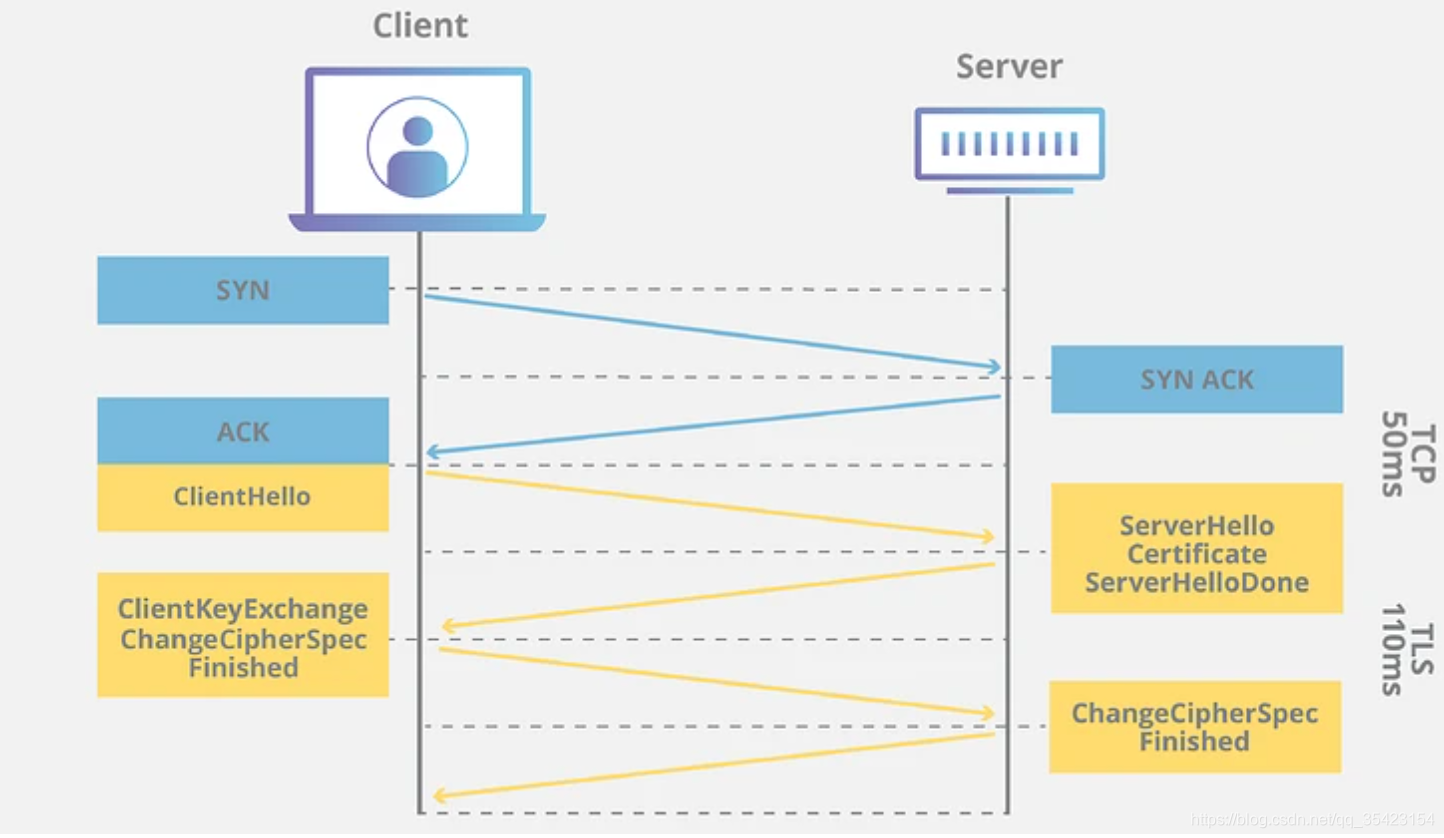
RTT 是 Round Trip Time 的缩写,通俗地说,就是通信一来一回的时间
而 QUIC 可以达成0RTT建立连接,第一个数据包就可以传输数据. 但是 QUIC 的 0RTT 不是没有条件的, 对于首次连接还是需要 1RTT 来进行密钥协商. 因此建连主要分为两个部分 首次连接 和 非首次连接
首次连接使用 DH 算法交换密钥, 过程如下:
- 客户端对于首次连接的服务端先发送client hello请求
- 服务端生成一个素数p和一个整数g,同时生成一个随机数为私钥,然后计算出公钥。服务端将公钥,p,g三个元素打包成为
config,后续发送给客户端 - 客户端随机生成一个自己的私钥,再根据 config 计算出自己的公钥
- 客户端使用自己的
私钥和 config 中读取的服务端公钥,生成后续数据加密用的密钥K - 客户端使用
密钥K加密业务数据,并追加自己的公钥,都传递给服务端 - 服务端根据自己的
私钥和客户端公钥计算出客户端加密用的密钥K, 解密数据 - 为了保证数据安全,上述生成的 密钥K 只会生成使用1次,后续服务端会按照相同的规则生成一套全新的公钥和私钥,并使用这组公私钥生成新的密钥M
- 服务端将新公钥和新密钥M加密的数据发给客户端,客户端根据新的服务端公钥和自己原来的私钥计算出本次的密钥M,进行解密
- 之后的客户端和服务端数据交互都使用密钥M来完成,密钥K只使用1次
非首次连接
因为首次连接时, 客户端储存了服务端的 config(服务器公钥/p/g), 因此后续的连接可以直接用 config 计算通信的秘钥. 从而跳过秘钥协商实现 0RTT. 注: config 有时间限制, 如果过期仍然需要首次连接的密钥交换
多路复用
3.0 的多路复用完美解决了队头阻塞的问题, 它跟 2.0 的多路复用一样在同一个连接上可以创建多个流. 不同的是 QUIC 协议是基于 UDP 的, 所以 每个流之间没有依赖.
也就是说就算一个 stream1 中发生了丢包, 虽然 stream1 丢失的包依然需要等待重传, 但是不影响其他 stream 的数据发送
前向安全
是指密钥泄露也不会让之前的数据被泄露, 只影响当前. 所以每次通讯的 密钥只会使用一次, 交互完之后将其销毁, 再重新生成. 这样即使密钥泄露, 对方也只能获取对应那条密钥的消息
前向纠错
TCP 是每次丢包重传, QUIC 是将每组数据包进行运算, 将结果作为一个 校验 和数据包发送. 如果这组数据丢包, 就可以通过校验与其他包来还原丢包数据
连接迁移
TCP 五元组(源IP,源端口,目的IP,目的端口,传输层协议)来唯一表示一条连接. QUIC 则是生成一个 64 位随机数作为连接唯一标识 , 这样就算切换网络五元组变化这个标识也不会变, 就可以快速重连
总结
HTTP 是一种超文本协议, 用于在网络中将发送方的超文本信息传输给接收端
HTTP1.0:
- 每次请求都需要重新建立 TCP 连接, 带来
重复建立 TCP 连接的性能消耗和队头阻塞的问题
HTTP1.1:
- 使用
Keep-Alive来复用 TCP 连接发送多次请求. 应用中可以通过不同域名来提高并发量, 但浏览器有限制 6 ~ 8 个并发请求数量的条件. 而同一条 TCP 中的请求-响应依然是阻塞的 管线化基于 Keep-Alive 将所有请求打包一次性发送到服务端, 解决请求阻塞的问题. 但服务端响应时还是必须按请求顺序依次返回, 由于性能问题管线化也没有被广泛使用
HTTP2.0:
多路复用引入帧和流的概念. 在同一个 TCP 连接中, 所有请求都基于流并可以承载不限数量的流, 流中的信息由二进制帧组成, 帧中会标识所属流, 从而实现乱序发送. 但 TCP 层面的队头阻塞仍然存在, 一个流中发生丢包, 可能阻塞整条 TCP 中的流- 通过 HPACK 算法进行
头部压缩, 同时发送和接收端共同维护头部表, 避免每次传递相同头部字段 - 利用
服务端推送实现一个请求服务端能够应答多个响应
HTTP3.0: 基于 UDP 实现拥有 TCP 优点的 QUIC 协议.
- 利用 UDP 面向无连接的特性, 配合首次连接 1RTT 实现
低延迟等待 - 跟 HTTP2.0 一样使用
多路复用完美解决队头阻塞. 因为 UDP 中流之间不会相互依赖, 一个流中丢包完全不影响其他流发送数据 - 通信过程中使用一次性秘钥来保证
向前安全, 就算当前通讯中密钥被劫持, 也不用担心之前的数据也会被窃取了 - 通过
向前纠错将数据包分为校验包和数据两部分, 数据丢包时可以通过其他数据包来还原(丢太多还是要重传). - 算法生成一个 64 为随机数作为连接标识符, 替代 TCP 中五元组作为标识符, 保证
连接迁移时能快速重连