

提到 TCP 协议大家印象最深刻的应该就是”可靠性”这三个字了, 因此为了保证”可靠性”真的是用了好多机制来保证😂 . 不知道当初设计 TCP 的大佬们看到现在的 QUIC 协议会不会觉得好气
那么为了实现可靠性, TCP 到底做了哪些事呢? 主要要是通过 数据序列号 / 确认应答 / 流量控制 / 拥塞控制 / 重发机制 这几个机制来实现的, 下面就一次聊聊这些机制到底在做些什么.
数据序列号和确认应答
首先 TCP 协议是面向字节流的, 而经过 TCP 协议的数据会被拆分到多个数据段中, 每个数据段中都会包含一个序列号的协议头, 这个序列号就是我们所说的数据序列号了.
那确认应答是啥呢? 在 TCP 中, 当发送端发送的数据到达接收端时, 接收端会回复一个确认应答的消息, 表示已收到消息. 而这个应答消息也就是我们常说的 ACK(Acknowledge character)报文段
ACK 是指 TCP 的报文到达确认, 确认接收到的数据的最高序列号,同时向发送端返回一个下次接收时期望的 TCP 数据包的序列号(也就是 ACK 的值)
那么在网络过程中, 数据的传输过程中大概会是这样:1
2
3
4
5主机 A 主机 B
---- 数据 1 ~ 100 ------>
<--- 确认应答(下一个101) ------
---- 数据 101 ~ 200 ------>
<--- 确认应答(下一个201) ------
但其实在网络, 并不会上述的过程中那么顺利, 那么当数据在传输过程中丢失了怎么办? 所以有了重传机制
重传机制
重传机制主要有四种方式: 计时重传 / 快速重传 / 带确认重传(SACK) / D-SACK
计时重传
计时重传是指在发送数据时, 启动一个计时器, 当超过指定时间后没有收到对方的 ACK 确认应答报文, 那么就会重新发送数据同时降低发送速率.
举例来说:
假如传输的数据 12345, 1 丢掉了, 2345 被接收到了, 因为丢掉了数据包 1 所以接收方没法发送 ACK 报文. 那么发送方也就只能等着接收方发 ACK, 双方就只能死等数据段 1, 从而造成超时. 而超时之后发送方并不知道丢了那些数据段, 就只能悲观的认为数据 1 之后的数据也都丢了, 那么就要重传所有数据段.
从上面的过程中, 我们可以发现计时重传会有两个问题:
- 只有等超时后才能重传
- 不知道重传数据范围
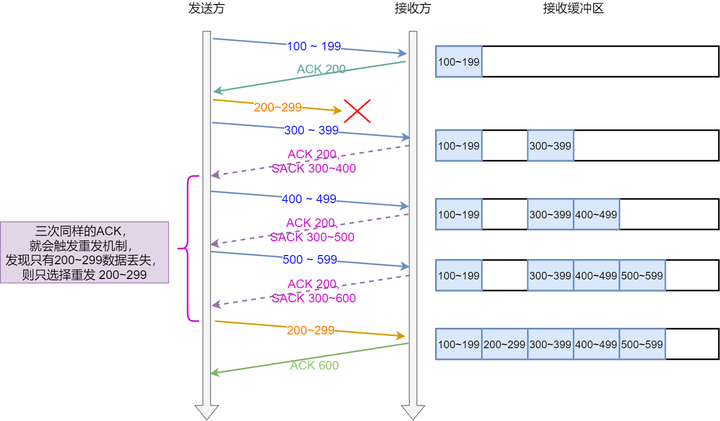
快速重传
快速重传是基于计时重传, 主要解决了要等待超时才能重传的问题. 所以快速重传的做法是: 当接收方收到乱序包时, 立即发送 ACK 表明下个期望接收的数据(其实就是丢失的那个数据). 而发送方连续收到三次相同的 ACK 就会重传, 不需要等到是计时器超时.
带确认重传(SACK)
上面的快速重传解决了超时的问题, 那么剩应该重传数据范围的问题. 那么 SACK 就是在快速重传的基础上, 增加一个 SACK 的头, 将已收到的数据报文段的序列号范围告诉发送方, 这样发送方就可以只重传丢失的数据
D-SACK
D-SACK 主要是为了告诉发送方哪些数据重复接收了. 上面不是已经有 SACK 告诉发送方哪些数据报文段是已接收了的吗, 为啥还需要 D-SACK? 因为在网络中我们的 ACK 报文和数据段报文都可能会丢失呀! 比如以下两种情况:
ACK 应答报文丢失:
- 当接收方分别收到数据 1 和 2, 并回复 ACK = 2 和 ACK = 3
- ACK 丢失了发送方一直收不到 ACK 自然无法触发快速重传
- 于是触发超时重传, 超时重传只好再重发一次数据 1. (造成重复数据)
- 接收方再次收到重发的数据, 响应 ACK = 3 和 SACK = 1 ~ 2
此时的 SACK 就会变成表示重复收到的数据包范围, 这样发送方就知道了原来是接收方的 ACK 报文丢失了
网络延迟:
- 发送方法送了数据 1234,
- 数据 2 延迟了一直没有到达接收方
- 数据 134 顺利达到于是接收方会分别回复三次 ACK = 2, SACK = 3 和 SACK = 3 ~ 4 触发到了快速重传
- 在快速重传的数据 2 达到之前, 先收到了之前延迟的数据 2, 在收到重发的数据 2 (造成重复数据)
- 接收方回复 ACK = 5 和 SACK = 2
此时 ACK已经到了 5, SACK 还是 2 说明这个是重复数据. 同时发送方也知道了不是发出去的包丢失了, 也不是 ACK 报文丢了, 而是网络延迟了
流量控制
流量控制是为了防止发送方发送的速率太快, 导致接收方的缓存区溢出. 基本原理就是让发送方知道接收方的缓存区大小, 以调整发送速率.
这一原理通过滑动窗口来实现的, 其中接收方的缓存区大小叫做接收窗口(rwnd)大小, 发送方的发送速率由发送窗口(swnd)大小决定. 发送窗口的大小不能大于接收窗口的大小, 否则接收方就处理不过来了
引入窗口的原因: 从上面传输数据的过程, 我们知道传输过程都是一来一回的, 所以数据的往返时间越长, 通讯效率就越差. 而窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值.
以发送方的窗口为例: 窗口相当于开辟一个缓存区域, 将以发送的数据保存在缓存区中, 在收到 ACK 应答之前必须一直保存, 直到收到应答才清除缓存, 然后按收到应答的数据字节向右滑动. 注: 两个窗口的大小都是放在操作系统内存缓冲区中的,而操作系统的缓冲区会被操作系统调整
窗口关闭(死锁)
当窗口不为 0 的应答丢失时,发送方会一直等待,而接收方以为发送方收到了则一直等待新数据,这样相互等待的过程就造成了死锁
解决方案:
用持续计时器来解决,每当收到接收方窗口为 0 时,都启动一个计时器时间一到发送方就主动询问接收方窗口大小。如果还是 0 就重置计时器;不为 0 则表示之前的报文丢失了,重置窗口,再重新开始发送
糊涂窗口
如果接收方太忙了,来不及取走接收窗口里的数据,那么就会导致发送方的发送窗口越来越小. 到最后接收方窗口大小只有几个字节了, 发送方还是义无反顾的发送几个字节的数据. 这就是糊涂窗口
于是,要解决糊涂窗口综合症,有下面两个办法:
- 让接收方不通告小窗口给发送方
- 当窗口大小 < Math.min(最大数据段数量MSS,缓存空间/2 ), 直接告诉发送方窗口为 0
- 让发送方避免发送小数据
- 要等到接收窗口大小 >= MSS
- 收到之前发送数据的 ACK 回包
拥塞控制
跟流量控制的区别在于, 拥塞控制作用于网络. 根据丢包情况和网络带宽防止过多数据注入网络,造成网络负载过大.
试想在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,然后进入恶性循环, 于是有了拥塞控制.
拥塞控制中, 会在发送方新增一个拥塞窗口(cwnd)的变量, 它随着网络拥塞程度动态变化. 注: 加入了拥塞窗口后, 发送窗口的值swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值
拥塞窗口 cwnd 变化的规则:
- 只要网络中没有出现拥塞,cwnd 就会增大
- 但网络中出现了拥塞,cwnd 就减少
那怎么判断网络出现拥塞了呢?
结合之前聊到的数据传递过程, 可以推断出当发送方没有及时收到 ACK 响应, 就可以认为是网络拥塞了
拥塞控制又控制些啥, 主要控制了四个算法: 慢启动 / 拥塞避免 / 快速重传 / 快速恢复,
慢启动
是指一点一点提高发送数据包的数量,发送方每收到一个接收方的 ACK 响应, 拥塞窗口大小就加倍,呈指数级增长.同时还会维护一个慢启动阈值(ssthresh)拥塞避免
发送方每收到一个接收方的 ACK 响应, 拥塞窗口大小就 + 1,趁线性增长,减缓拥塞窗口增长速度慢启动阈值会决定使用慢启动还是拥塞避免:
- 当拥塞窗口大小 < 慢启动阈值, 使用慢启动
- 拥塞窗口大小 >= 慢启动阈值, 使用拥塞避免
快速重传
当网络发生拥塞,接收方收到了三次重复 ACK,触发快速重传机制.
TCP 会认为这种情况没有很严重, 则调整拥塞窗口和慢启动阈值:- 拥塞窗口大小 = 拥塞窗口大小 / 2
- 慢启动阈值 = 拥塞窗口大小
接着进入快速恢复
快速恢复
在基于快速重传将拥塞窗口大小 + 3(因为收到了三个数据包),重传丢失的数据包,收到 ACK 恢复了就进入拥塞避免算法,再次尝试让拥塞窗口增大
如果网络拥塞到触发了计时重传, 那就一棒回到解放前, 重新开始慢启动来大幅减少数据流.同时慢启动阈值和拥塞窗口大小也会发生变化:
- 慢启动阈值 设为 拥塞窗口大小/2
- 拥塞窗口大小 重置为 1
总结
TCP 的可靠性是由:
序列号和确认应答来保证数据到达接收方流量控制用滑动窗口来防止发送方发送速率过快导致接收方处理不过来拥塞控制用慢启动 / 拥塞避免 / 快速重传 / 快速恢复来防止大量数据在网络中造成拥堵, 从而造成更多数据延迟/丢包带来恶性循环